Tutorial Membuat Interpreter dan Compiler (bagian 2)
part 1 part 2 part 3 part 4 part 5 part 6 part 7 part 8 part 9
Source code untuk artikel ini:
expr1.zip
Memahami langkah pembuatan interpreter
Jika Anda punya niat untuk membaca tutorial ini, saya asumsikan Anda
sudah tahu cara kerja interpter. Interpreter membaca source dalam bahasa
X (misalnya file.php, program.py, dsb). Interpreter akan menjalankan
program input tersebut, dan menghasilkan output. Kira-kira seperti ini
diagramnya:

Proses itu sudah jelas, tapi Anda membaca tutorial ini karena ingin
tahu apa yang ada dalam sebuah interpreter. Sebuah interpreter terdiri
atas bagian parser, dan interpreter. Parser menghasilkan sebuah tree
yang disebut dengan
parse tree. Jadi, isi sebuah interpreter bisa digambarkan seperti ini:

Bagian yang umumnya memakan banyak waktu adalah menuliskan bagian parser, oleh karena itu banyak program
parser generator
yang dikembangkan (beberapa di antaranya YACC, Bison,dan ANTLR). Sebuah
parser generator hanya perlu diberikan grammar sebuah bahasa, lalu akan
menghasilkan kode program untuk parsing. Kode program yang dihasilkan
bisa dikompilasi bersama-sama dengan kode program kita yang lain.

Jadi dalam gambaran totalnya, peran parser generator adalah seperti ini:

Dengan adanya parser generator, kita hanya perlu berkonsentrasi pada
dua hal: seperti apa syntax bahasa kita, dan bagaimana mengeksekusi tree
yang dihasilkan oleh parser untuk bahasa tersebut.
Bahasa paling sederhana: KALKULATOR
Kita akan mengimplementasikan bahasa yang sangat sederhana, yang
hanya berfungsi sebagai kalkulator. Pertama kita akan membuat versi
interpreter, lalu membuat versi compilernya. Grammar kalkulator ini
sangat sederhana, hanya sebuah ekspresi '+', '-' dan '*'. Saya sengaja
tidak membuatkan '/' untuk bahan latihan. Ketika dijalankan program akan
mencetak setiap ekspresi yang dievaluasi. Jadi program:
1+2
2*3
(8-2)*(7-2)
akan menghasilkan: 3, 6, dan 40
ANTLR
Untuk memudahkan, dalam tutorial ini kita gunakan tools ANTLR
http://www.antlr.org/
yang berbasis GUI yaitu Antlrworks. Tools ini sangat mudah dipakai dan
sudah cukup matang. Versi command line ANTLR sudah dirilis sejak 1992
dan GUI modern dikembangkan sejak 2005. Sebelumnya sebenarnya sudah ada
versi GUI, tapi masih kurang matang, sehingga dibuatlah versi GUI yang
modern.
Bagi Anda yang masih kurang lancar dalam memahami grammar, ANTLR
sangat bisa membantu, Anda bisa mencoba langsung grammar Anda sebelum
mulai membuat program satu baris pun. Jika ada fitur yang saya jelaskan
tapi Anda belum paham, Anda bisa mencoba-coba mengubah grammar dan
langsung mencoba melihat visualisasinya. Jadi jika Anda merasa artikel
ini terlalu cepat, cobalah berhenti dan mencoba hasilnya di ANTLRWorks.
Saya tidak akan memberi tutorial bagaimana cara memakai ANTLRWorks.
Anda bisa mencoba-coba sendiri. Untuk mengikuti tutorial ini, download
saja source code yang saya sediakan dan buka file berekstensi .g dengan
ANTLRWorks.
ANTLR dan ANTLRWorks hanyalah salah satu tools yang tersedia. Jika
Anda sudah mahir, tools apapun akan sama saja. Programmer yang baik
tidak akan dibatasi oleh tools.
Cara menjalankan ANTLRWorks tergantung pada OS yang Anda gunakan. Di
Mac OS X/Windows, jika sudah diset dengan benar, Anda bisa mengklik file
antlrworks-1.2.3.jar, dan GUI akan muncul. Jika cara tersebut gagal,
mungkin Anda perlu menjalankan dari
command line, caranya:
java -jar /path/to/antlrworks-1.2.3.jar
Berikut ini grammar yang akan kita pakai (ini versi 1, lihat file
Expr_1.g) sebagai dasar bagi interpreter dan compiler kita (catatan,
baris yang diawali // adalah komentar):
grammar Expr;
// START:stat
prog: stat+ ;
stat: expr NEWLINE
| NEWLINE
;
// END:stat
// START:expr
expr: multExpr (('+'|'-') multExpr)*
;
multExpr
: atom ('*' atom)*
;
atom: INT
| '(' expr ')'
;
// END:expr
// START:tokens
INT : '0'..'9'+ ;
NEWLINE:'\r'? '\n' ;
WS : (' '|'\t'|'\n'|'\r')+ {skip();} ;
// END:tokens
Mari kita bahas grammarnya. Sebuah program <prog> terdiri atas
banyak pernyataan <stat>+ (simbol plus artinya satu atau lebih),
sebuah pernyataan boleh sebuah ekpresi <expr> atau sebuah baris
kosong (NEWLINE). Anda juga bisa melihat Syntax Diagram dari sebuah
rule, misalnya prog akan tampak seperti ini:


Karena Anda bisa melihat sendiri syntax diagram-nya di ANTLRWorks, saya tidak akan menampilkan sisanya.
Sebuah ekspresi terdiri dari pernyataan perkalian <multExpr>
yang diikuti oleh plus/minus ekpresi yang lain. Tapi plus dan minus itu
tidak wajib, jadi kita tambahkan * yang artinya nol atau lebih.
Pernyataan perkalian sendiri terdiri atas <atom> yang (mungkin)
dikalikan dengan atom lain, karena tidak harus dikalikan atom lain,
maka kita tambahkan juga *. Aturan terakhir adalah <atom> yang
bisa berupa sebuah integer, atau ekspresi lain dalam tanya kurung.
Berikutnya kita perlu mendefinisikan token. Dalam kasus ini yang
menjadi token adalah INT (0-9), NEWLINE (boleh \r\n yang merupakan versi
DOS atau \n saja yang merupakan versi UNIX). Kita juga mengijinkan
spasi ada di antara ekspresi, jadi 1+2 sama dengan 1 + 2, untuk itu kita
perlu mendefinisikan karakter apa saja yang perlu dilewatkan (skip),
dalam kasus ini kita mengabaikan spasi, tab, dan karakter baris baru.
Kita bisa langsung mencoba grammar ANTLR ini, dengan menggunakan
ANTLRWorks. Coba pilih menu Debugger, lalu pilih Debug. Masukkan teks,
misalnya 1+2. Perhatikan bahwa Anda harus mengakhiri sebuah ekspresi
dengan karakter baris baru (enter) setelah ekspresi. Anda bisa
menjalankan grammar langkah per langkah, atau langsung saja klik pada
tombol END. Hasilnya sebuah pohon akan ditampilkan, pohon ini dinamakan
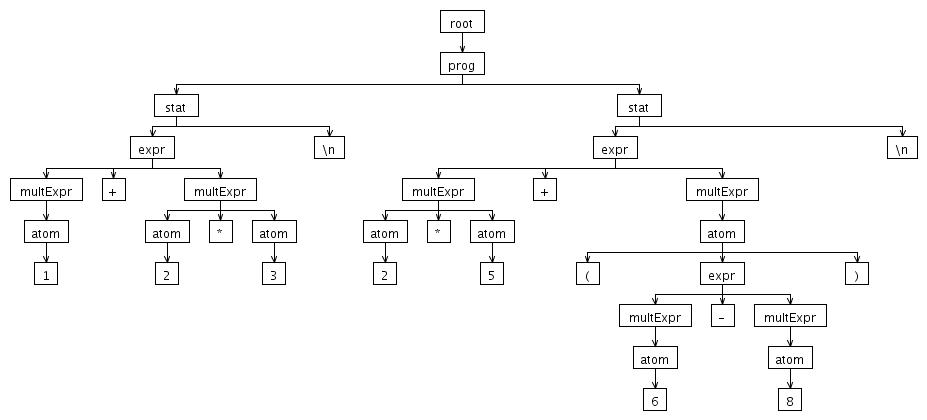
Pohon Parsing (Parsing Tree). Silakan Anda mencoba-coba aneka ekspresi
lain, termasuk ekspresi multi baris, supaya bisa melihat bagaimana pohon
untuk setiap ekspresi.
Berikut ini adalah gambar pohon yang dihasilkan oleh 1 + 2 * 3.
Gambar pohon ini dihasilkan langsung oleh ANTLRWorks (saya tidak
menggambarnya manual).

AST
Jika diperhatikan karakter yang tidak penting juga masuk dalam pohon
ini, yaitu karakter '\n'. Ada juga node yang tidak penting, yaitu atom.
Jika Anda membuat bahasa yang lebih rumit, misalnya bahasa C, maka
karakter seperti '{', '}', ';' yang tidak penting juga akan masuk dalam
parse tree.
Kita mengatakan karakter itu tidak penting karena gunanya hanya untuk
memisahkan blok, dan dalam bentuk pohon, sudah jelas bahwa blok-blok
tersebut terpisah.
Sebelum masuk tahap pemrosesan, kita perlu mengubah pohon tersebut ke bentuk AST (
abstract syntax tree)
dengan membuang hal-hal yang tidak perlu, dan mungkin mengorganisasi
tree menjadi bentuk yang lebih baik (lebih mudah diproses, misalnya
menukar node kiri dan kanan, dsb). Jika kita menggunakan tools tertentu
(misalnya Bison) kita menulis kode untuk mengubah parse tree menjadi
AST, tapi untungnya ANTLR sudah cukup canggih, sehingga kita cukup
menambahkan aturan untuk membuat pohon.
AST yang saya inginkan untuk 1 + 2 * 3 adalah:

Dan jika ada dua baris (saya menambahkan satu baris baru: 2 * 5 + (6 - 8)) :
1 + 2 * 3
2 * 5 + (6 - 8)
Saat ini parse tree sudah terlalu kompleks:

Sedangkan AST yang diharapkan adalah seperti ini:

Perhatikan bahwa tanda kurung juga tidak ada lagi (tidak lagi penting, karena dalam bentuk tree sudah jelas presedensinya).
Ada beberapa perubahan yang diperlukan untuk menghasilkan AST. Pertama di bagian options, kita tambahkan opsi
output = AST, dan
ASTLabelType = CommonTree. Ini artinya kita meminta ANTLR menghasilkan AST, dengan tipe node AST-nya adalah
CommonTree.
Jika kita mau, kita juga bisa membuat sendiri jenis node untuk tree
kita sendiri, tapi saat ini hal tersebut tidak diperlukan.
Berikutnya, kita perlu menentukan seperti apa bentuk tree kita. Dalam
kasus ini, karena ada banyak ekspresi, saya ingin di bagian akar (root)
adalah EXPRESSION
LIST, dan terdiri atas banyak EXPRESSION. Jika dilihat kembali, tidak ada rule yang bernama EXPRESSION ataupun EXPRESSIONLIST, jadi kita perlu mendefinisikan kedua nama tersebut di bagian
tokens.
Kita juga ingin agar INT menjadi nama node untuk literal integer.
Setiap nama yang didefinisikan di bagian tokens akan memiliki konstanta
bertipe integer di file parser yang dihasilkan ANTLR.
options {
output = AST;
ASTLabelType =CommonTree;
}
tokens {
EXPRESSION_LIST;
EXPRESSION;
INT;
}
Kita perlu mengubah pohon stat menjadi pohon EXPRESSION_LIST, yang
terdiri atas banyak EXPRESSION. Caranya kita gunakan operator
->
milik ANTLR. Operator ini digunakan setelah sebuah rule, untuk
menentukan bentuk tree untuk rule tersebut. Umumnya bentuknya adalah
^(ROOT rules), yang artinya, jadikan ROOT sebagai akar dan rules sebagai anak-anaknya. Contohnya seperti ini:
// START:stat
prog: stat+ -> ^(EXPRESSION_LIST stat+);
stat: expr NEWLINE -> ^(EXPRESSION expr)
| NEWLINE
;
// END:stat
Bagian pertama
stat+ -> ^(EXPRESSION_LIST stat+); artinya, node-node yang berupa stat, dikumpulkan dibawah node yang bernama EXPRESSION_LIST. Bagian kedua
expr NEWLINE -> ^(EXPRESSION expr) artinya Node expr ditaruh dibawah node EXPRESSION, dan kita mengabaikan karakter NEWLINE.
Kita juga ingin agar '+' dan '-' memiliki nodenya sendiri. Jadi jika
ada 11+12, kita ingin agar punya Node '+' yang anak kirinya adalah node
11 dan anak kanannya adalah node 12. Untuk hal ini, ANTLR memiliki
shortcut. Agar '+' dan '-' menjadi node, cukup tambahkan karakter
^ di bagian grammar yang ingin dijadikan root node.
// START:expr
expr: multExpr (('+'|'-')^ multExpr)*
;
Sama halnya dengan '*', kita juga ingin agar * memiliki nodenya sendiri
multExpr
: atom ('*'^ atom)*
;
Dan terakhir, kita ingin membuang kurung buka dan kurung tutup,
karena urutan evaluasi sudah jelas dalam tree. Untuk membuangnya, kita
nyatakan bahwa
'(' expr ')' -> expr, yang artinya: jika
ada kurung buka, lalu expr, lalu kurung tutup, cukup hasilkan expr saja
(dengan kata lain buang kurung buka dan tutupnya).
atom: INT
| '(' expr ')' -> expr
;
// END:expr
Sekarang kita bisa mengklik tab AST di ANTLRWorks, dan hasil AST-nya adalah seperti ini.
Nah sekarang kita sudah punya tree yang bagus. Berikutnya adalah
bagaimana mengeksekusi tree tersebut? Ada dua cara: pertama adalah
interpretasi, dan kedua adalah kompilasi. Namun kita perlu menghasilkan
dulu source code parsernya, caranya cukup klik menu Generate lalu pilih
Generate Code. ANTLR akan membuat tiga buah file, yaitu file Lexer, file
Parser, dan file Tokens.

Catatan: Java hanyalah salah satu bahasa yang didukung ANTLR. ANTLR
juga bisa membuat parser dalam bahasa C, C#, Python, JavaScript, dan
ActionScript.
Menulis Kode
Nah sekarang kita perlu menuliskan kode dalam bahasa Java. Kode-kode berikut ini ada pada file
ExprLang.java.
Setiap parser pasti punya kode inisialisasi, kode inisialisasi ini akan
sama untuk aneka jenis bahasa, sehingga tidak akan dijelaskan lagi di
bagian berikutnya.
public static void main(String argv[]) throws Exception {
ExprLexer lex = new ExprLexer(new ANTLRFileStream(argv[0]));
CommonTokenStream tokens = new CommonTokenStream(lex);
ExprParser g = new ExprParser(tokens);
ExprParser.prog_return r = g.prog();
CommonTree ct = (CommonTree)r.getTree();
}
Baris pertama dalam sebuah fungsi main membuat sebuah lexer (dalamkasus ini
ExprLexer), yang fungsinya memecah string menjadi bagian-bagiannya (menjadi INT, '*', '+', '-', dsb). Baris kedua membuat object
CommonTokenStream
yang diberikan ke parser (ini adalah sebuah adapter, Anda tidak perlu
mengetahui internalnya kecuali ingin mengubah kode ANTLR). Baris ketiga
adalah bagian untuk mengkonstruksi parser, dan baris ke empat adalah
baris yang penting, baris di mana proses parsing itu sendiri dipanggil:
ExprParser.prog_return r = g.prog();
Kita meminta nilai kembalian parser dimulai dari aturan
prog. Setelah itu kita bisa mendapatkan Tree (AST) dengan menggunakan
r.getTree(). Tree yang kita pakai adalah Tree standar bawaan ANTLR, jadi kita memakai
CommonTree. Setelah memiliki root dari tree, kita bisa mengevaluasi ekspresi dengan mudah. Saya tidak akan menjelaskan semua method milik
CommonTree, penjelasan lengkap ada di dokumentasinya di:
http://www.antlr.org/api/Java/classorg_1_1antlr_1_1runtime_1_1tree_1_1_common_tree.html
Method-method yang akan saya pakai adalah:
getChildren,
getChilCount,
getChild,
getType, dan
getText. Berikut ini penjelasan singkatnya:
- Method
getChildren untuk mendapatkan List of children yang bisa diiterasi menggunakan format loop Java (for (Tree x: e.getChildren()) {}). Sebagai catatan, Anda akan melihat banyak casting tipe Object ke CommonTree, ketika ANTLR ditulis, Java 1.5 belum dirilis, sehingga fitur Generic milik Java belum dipakai. Mereka saat ini sudah mulai beralih ke JDK 1.5.
- Method
getChildCount digunakan untuk mendapatkan jumlah anak. Berguna untuk menentukan apakah misalnya pernyataan if memiliki else atau tidak.
- Method
getChild digunakan untuk mendapatkan anak ke-n.
- Method
getType digunakan untuk mendapatkan konstanta
integer tipe node. Nilainya terdefinisi (tidak nol) jika node tersebut
diberi nama dibagian tokens. Hasil kembalian method ini bisa
dibandingkan dengan konstanta integer yang dihasilkan ANTLR dalam format
NamaGrammarLexer.KONSTANTA (dalam contoh ini misalnya ExprLexer.INT)
- Method
getText digunakan untuk mendapatkan teks node (misalnya node + akan memiliki teks +). Ketika nanti node variabel diperkenalkan, getText bisa digunakan untuk mendapatkan nama variabel.
Mari kita mulai memproses tree. Kita memiliki banyak ekspresi dalam satu file, maka kita buat method
evaluateExprList, method ini hanya akan memanggil
evaluateExpression yang tugasnya adalah mengevaluasi ekspresi itu sendiri.
void evaluateExprList(CommonTree exprlist) {
for (Object e: exprlist.getChildren()) {
System.out.println("Result: " +
evaluateExpression((CommonTree)e));
}
}
Kalau kita lihat dari gambar AST yang dihasilkan oleh Antlr, misalnya pohon ini:
kita melihat bahwa ada suatu node dengan nama EXPRESSION yang tidak
terlalu berguna untuk saat ini. Gunanya hanyalah agar terlihat bahwa
node di bawahnya adalah sebuah ekspresi. Saya sengaja membuat node ini
untuk pengembangan versi berikutnya, di mana setiap baris belum tentu
berisi ekspresi. Kita hanya perlu melewati node itu dengan mengambil
anaknya yang pertama.
int evaluateExpression(CommonTree expr) {
debug("Evaluate Expression "+expr.getText());
return evaluateExpr((CommonTree)expr.getChild(0)) ;
}
Fungsi
evaluateExpr adalah fungsi yang melakukan komputasi. Ini sangat mudah, karena pada dasarnya hanya ada dua kasus: INTEGER, dan OPERATOR.
Pertama, jika isi node adalah integer, maka hasilnya adalah nilai integer itu sendiri (di Java kita memakai
Integer.parseInt untuk mengubah string menjadi integer)
if (expr.getType()==ExprLexer.INT) {
return Integer.parseInt(expr.getText());
}
Kedua, jika isi node adalah operator ('+' atau '-' atau '*') berarti
nilai ekspresi adalah nilai anak pertama dioperasikan
(ditambah/dikurang/dikali) dengan anak kedua:
if (expr.getText().equals("+")) {
return evaluateExpr((CommonTree)expr.getChild(0)) +
evaluateExpr((CommonTree)expr.getChild(1));
}
if (expr.getText().equals("-")) {
return evaluateExpr((CommonTree)expr.getChild(0)) -
evaluateExpr((CommonTree)expr.getChild(1));
}
if (expr.getText().equals("*")) {
return evaluateExpr((CommonTree)expr.getChild(0)) *
evaluateExpr((CommonTree)expr.getChild(1));
}
Cara Berpikir
Perhatikan bahwa algoritma ini sangat sederhana, Anda hanya perlu
berpikir: di Node ini saya harus melakukan apa? Anda jangan melihat
kompleksitas semu. Jika Anda berpikir bahwa untuk membuat kalkulator
seperti ini Anda harus memikirkan aneka kombinasi yang ada, seperti 4*7,
4+7, 4+(7), (4)+7, dst, maka cara berpikir Anda masih salah. Ingatlah
bahwa proses parsing menghasilkan pohon, sehingga Anda harus berpikir
bagaimana melakukan aksi dalam suatu node di pohon tersebut.
Mengkompilasi
Untuk mengkompilasi interpreter ini, Anda perlu file
antlr-runtime-3.1.3.jar (tergantung versi terbaru saat ini). Anda perlu
memberikan path ke file tersebut, di Linux/Mac/BSD, kira-kira seperti
ini:
javac -classpath /path/to/antlr-runtime-3.1.3.jar:. ExprLang.java
di Windows, kira-kira seperti ini:
javac -classpath c:\path\to\antlr-runtime-3.1.3.jar;. ExprLang.java
Tentu saja Anda juga bisa menggunakan Netbeans, atau Eclipse atau IDE
apapun. Jangan lupa menambahkan antlr-runtime-3.1.3.jar ke bagian
Library/Classpath.
Untuk menjalankan programnya dari command line:
java -classpath /path/to/antlr-runtime-3.1.3.jar:. ExprLang test.e
Di mana test.e adalah file teks yang berisi baris-baris ekspresi.
Selesai sudah interpreter yang sangat sederhana. Saya sengaja
menyertakan pernyataan debug agar pembaca dapat memahami alur eksekusi.
Total baris, tanpa debug hanyalah 60 baris, ditambah dengan file grammar
Expr.g totalnya hanya 100 baris. Mudah bukan?